





本文主要讲解有栈线程的实现原理,以云风实现的coroutine为例。在讲解之前,本文会先描述一些基本的概念,保证读者能够轻松的理解coroutine的实现。
协程
关于协程的概念,在网上没有找到正式的解释,下面就说说个人的理解,(有栈)协程可以理解为一个用户态下的线程,在用户态下进行线程(协程)的上下文切换。但是和传统的线程不同的是:线程是抢占式执行,当发生系统调用或者中断的时候,交由OS调度执行;而协程是通过yield主动让出cpu所有权,切换到其他协程执行。
进程、线程
进程地址空间
一般来说一个进程的地址空间有这几个默认区域:
- 栈:栈用于维护函数调用的上下文,包括函数的参数,局部变量等等。
- 堆:用来容纳程序中动态分配的内存区域,当程序使用malloc和new分配的内存就来自于堆里
- 可执行文件映像。
- 保留区,是对内存中受到保护而禁止访问的内存区域的总称。
下图是linux下一个进程的典型内存布局: 在经典的操作系统中,栈总是 向下增长 ,从高地址向低地址增长,其中栈顶指针存储在 [E|R]SP 寄存器中,而堆则总是 向上增长 ,从低地址向高地址增长。


栈的增长方式
栈在程序运行中具有举足轻重的地位,最重要的,栈保存了一个函数调用所需要维护的信息,这常常被称为堆栈帧,堆栈帧一般包括下面几方面内容:
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 保存的上下文:包括在函数调用前后需要保存不变的寄存器的值
一个函数的堆栈帧用 [E|R]SP,[E|R]BP ,这两个寄存器划定范围,[E|R]SP始终指向栈顶的位置称为栈指针寄存器,[E|R]BP指向堆栈帧的一个固定位置,[E|R]BP 又被称为帧指针,一般函数中的局部变量靠 [E|R]BP 加上偏移量寻找。
[E|R]SP表示esp或者rsp寄存器,esp表示32位x86架构下的栈指针寄存器,rsp表示64位x86架构下的栈指针寄存器,同理于[E|R]BP。 帧指针并不是必须的, x86-64过程中的栈帧通常有固定的大小,在调用过程中栈指针保持固定的位置,使得可以通过相对于栈指针的偏移量来访问数据^1。
下面我们就简单讲解一下当程序调用一个简单的函数时,线程中的栈是如何增长的。假设有一个foo函数
int foo(int m, int n){ int a = 0; // #i .... }
该函数对应的堆栈帧的内存空间如下所示,一个函数的堆栈帧增长过程是这样的:
- 把所有或一部分参数加入栈中,如果有其他参数没有入栈,那么使用某些寄存器传递
- 把当前指令的下一条指令地址压入栈中
- 跳转到函数体执行:
- 把[e|r]bp压入栈中,指向上一个函数堆栈帧中的帧指针的位置
- 保存调用前后需要保存不变的寄存器的值
- 将局部变量压入栈中
- ...
当函数调用返回之后,相应的函数堆栈帧也会弹出,弹出的流程不是本篇文章的重点,在此就不详细讲解,感兴趣的推荐看 程序员的自我修养 中讲解堆栈的部分。


线程
一个标准的线程由线程id、程序计数器(PC)、寄存器集合和栈组成。
每个线程类似一个独立进程,不同的是线程之间共享地址空间,能够访问到相同的数据。线程之间共享进程的内存空间(包括代码段、数据段、堆等)以及以下进程级的资源(如打开文件和信号)。
一个经典的进程和线程的关系如下图所示:

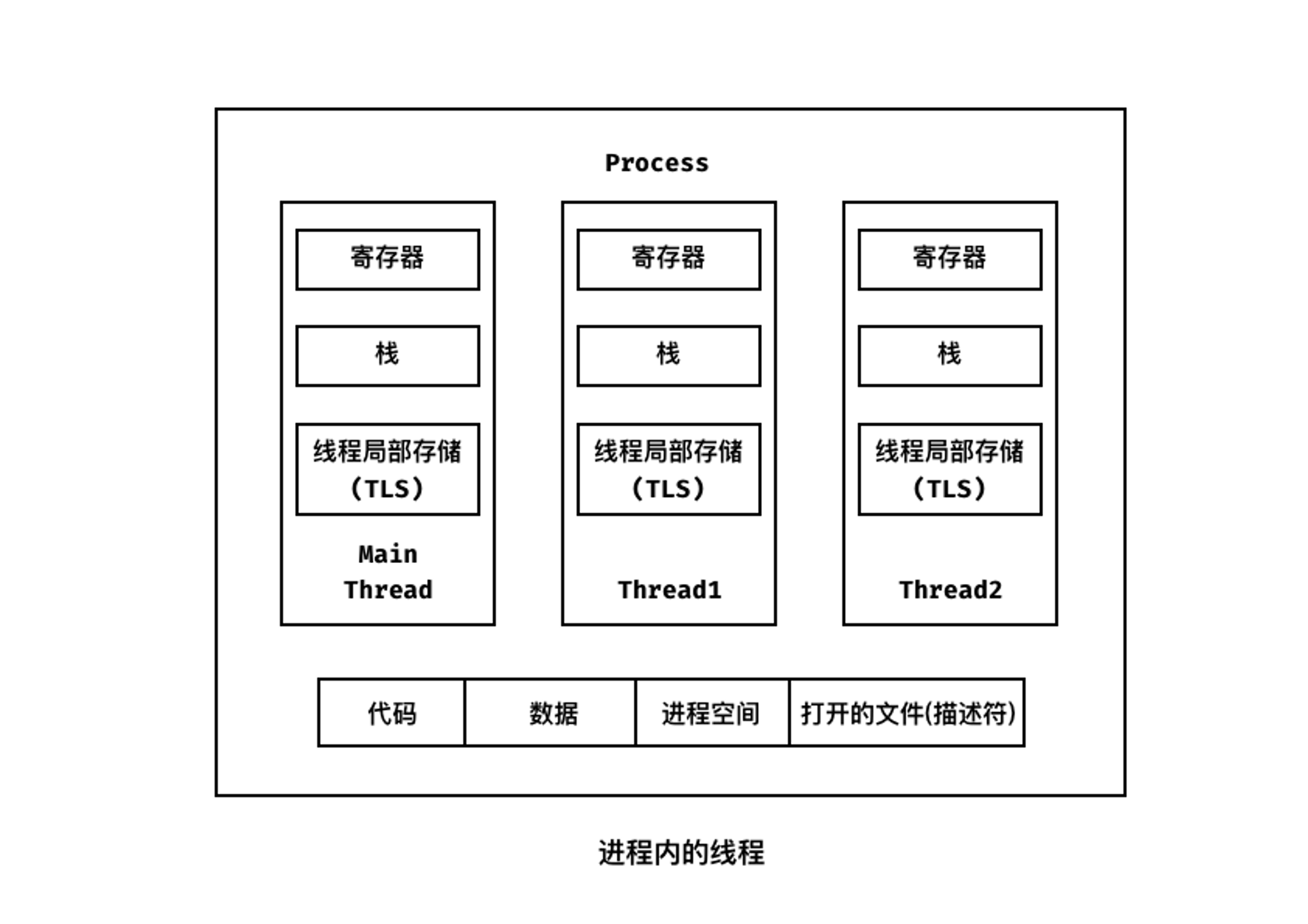
线程上下文切换
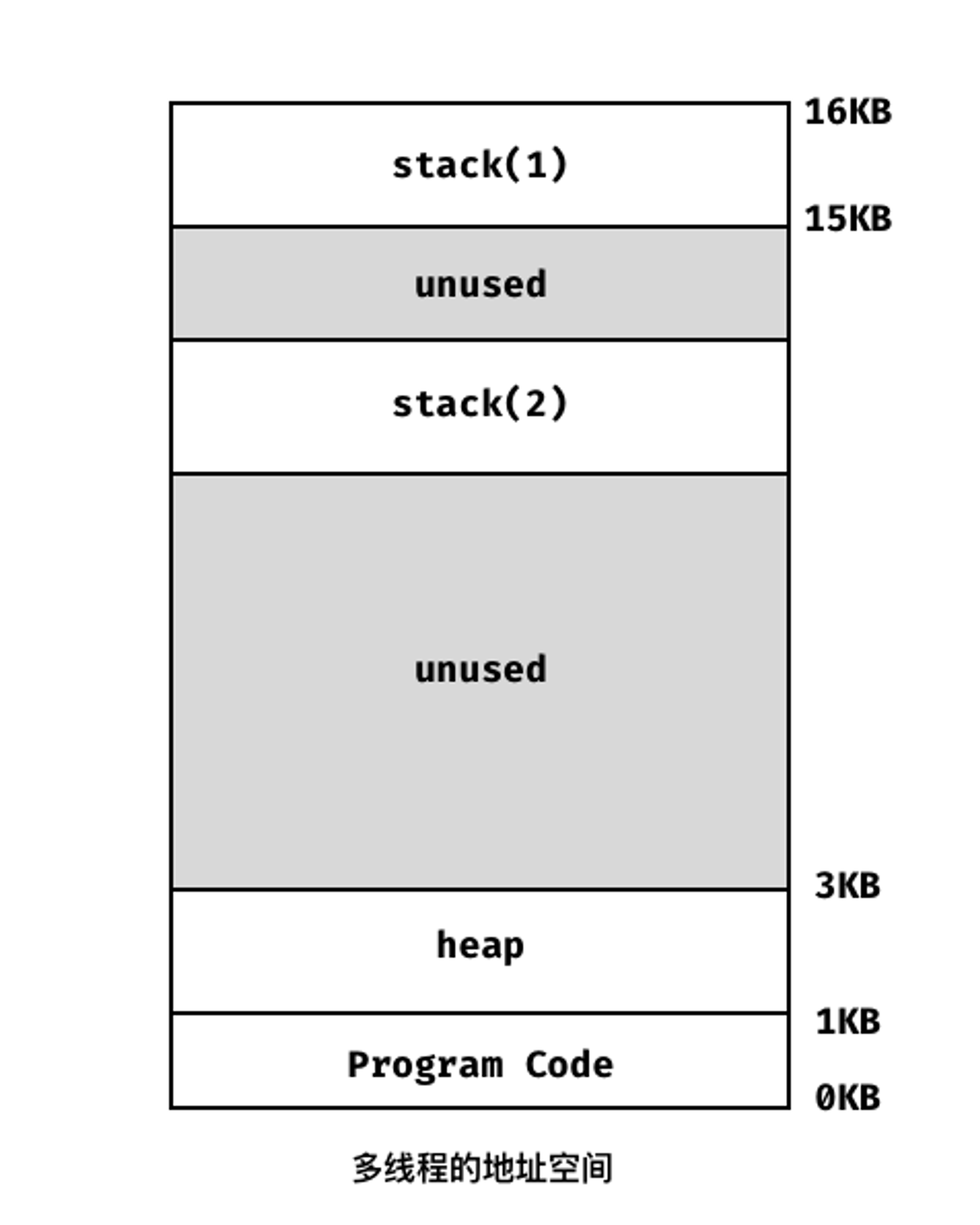
假设有2个线程运行在一个处理器上,从运行一个线程(T1)切换到另一个线程(T2)时,一定会发生上下文切换。对于进程,我们需要将状态保存到进程控制块(PCB)中,现在我们需要一个或多个线程控制块(TCB)来保存每个线程的状态,但是和进程上下文切换相比,线程在进行上下文切换的时候地址空间保持不变(即不需要切换当前使用的页表)。一个拥有多线程的进程的地址空间,如下图所示,我们可以看到每个线程拥有有自己的栈。

实现协程的理论依据
有栈协程就是实现了一个用户态的线程,用户可以在堆上模拟出协程的栈空间,当需要进行协程上下文切换的时候,主线程只需要交换栈空间和恢复协程的一些相关的寄存器的状态就可以实现一个用户态的线程上下文切换,没有了从用户态转换到内核态的切换成本,协程的执行也就更加高效。
ucontext
我们参考的协程实现是云风大佬编写的coroutine,源码只有不到200行,很适合用来阅读学习。在这个版本的coroutine中,使用ucontext族函数实现。我们先来简单的看一下这个函数族的基本功能。该部分参考自博客^2。
在类System V环境中,在头文件< ucontext.h > 中定义了两个结构类型,mcontext_t 和 ucontext_t和四个函数getcontext(),setcontext(),makecontext(),swapcontext().利用它们可以在一个进程中实现用户级的线程切换。 ucontext_t 结构体定义如下:
typedef struct ucontext { struct ucontext *uc_link; sigset_t uc_sigmask; stack_t uc_stack; mcontext_t uc_mcontext; ... } ucontext_t;
当当前上下文(如使用 makecontext 创建的上下文)运行终止时系统会恢复uc_link指向的上下文;uc_sigmask为该上下文中的阻塞信号集合;uc_stack为该上下文中使用的栈;uc_mcontext保存的上下文的特定机器表示,包括调用线程的特定寄存器等。
下面讲解四个函数的作用,详细的函数使用方法参考man手册:
1. 初始化ucp结构体,将当前的上下文保存到ucp中
int getcontext(ucontext_t *ucp);
2. 修改用户线程的上下文指向参数ucp,在调用makecontext之前必须调用getcontext初始化一个ucp,并且需要分配一个栈空间给初始化后的ucp,当上下文通过setcontext或者swapcontext激活后,就会紧接着调用第二个参数指向的函数func,参数argc代表 func所需的参数,在调用makecontext之前你需要初始化参数ucp->uc_link,这个参数表示func()执行之后,用户线程将要切换到ucp->uc_link所代表的上下文,其实是隐式的调用了setcontext函数。
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
3. 设置当前的上下文为ucp,setcontext的上下文ucp应该通过getcontext或者makecontext取得,如果调用成功则不返回。
int setcontext(const ucontext_t *ucp);
4. 保存当前上下文到oucp结构体中,然后激活upc上下文。
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
写个简单的例子来看一下如何使用:
#include <ucontext.h> #include <stdio.h> int func(void *arg) { puts("this is func"); } void coroutine_test() { char stack[1024 * 128]; ucontext_t child, main; // 获取当前上下文 getcontext(&child); // 分配栈空间 uc_stack.ss_sp 指向栈顶 child.uc_stack.ss_sp = stack; child.uc_stack.ss_size = sizeof(stack); child.uc_stack.ss_flags = 0; // 指定后继上下文 child.uc_link = &main; // child.uc_link = NULL; makecontext(&child, (void (*)(void))func, 0); //切换到child上下文,保存当前上下文到main swapcontext(&main, &child); // 如果设置了后继上下文,func函数指向完后会返回此处 如果设置为NULL,就不会执行这一步 puts("this is coroutine_test"); } int main() { coroutine_test(); return 0; }
程序的执行结果为:
this is func this is coroutine_test
coroutine实现
本文不打算详细讲解coroutine的代码实现,具体的实现细节大家可以参考文章^3,本文的代码注释也来自这篇文章,建议看完本节之后再阅读该文章来了解代码实现细节。通过学习了前几节讲到的基础知识,相信大家能够比较轻松的看懂协程代码的实现。本小节主要从整体的角度来讲解coroutine的实现。
coroutine例子
#include "coroutine.h" #include <stdio.h> struct args { int n; }; static void foo(struct schedule * S, void *ud) { struct args * arg = ud; int start = arg->n; int i; for (i=0;i<5;i++) { printf("coroutine %d : %d\n",coroutine_running(S) , start + i); // 切出当前协程 coroutine_yield(S); } } static void test(struct schedule *S) { struct args arg1 = { 0 }; struct args arg2 = { 100 }; // 创建两个协程 int co1 = coroutine_new(S, foo, &arg1); int co2 = coroutine_new(S, foo, &arg2); printf("main start\n"); while (coroutine_status(S,co1) && coroutine_status(S,co2)) { // 使用协程co1 coroutine_resume(S,co1); // 使用协程co2 coroutine_resume(S,co2); } printf("main end\n"); } int main() { // 创建一个协程调度器 struct schedule * S = coroutine_open(); test(S); // 关闭协程调度器 coroutine_close(S); return 0; }
核心对象
- struct schedule* S 协程调度器
struct schedule { char stack[STACK_SIZE]; // 运行时栈,此栈即是共享栈 ucontext_t main; // 主协程的上下文 int nco; // 当前存活的协程个数 int cap; // 协程管理器的当前最大容量,即可以同时支持多少个协程。如果不够了,则进行2倍扩容 int running; // 正在运行的协程ID struct coroutine **co; // 一个一维数组,用于存放所有协程。其长度等于cap };
调度器中包含协程运行时的共享栈stack,共享栈可以认为所有的协程在运行时用的都是同一块栈,当调用协程的时候,将自己的栈拷贝到共享栈即可。当协程切出时,将栈空间再复制出来。
还包括主协程上下文,可以认为是协程执行完毕之后回到的上下文。
以及一个一维数组,用来存放调度器包括的所有协程。
2. coroutine协程
coroutine结构体包括协程需要执行的函数,协程自己的上下文,用于上下文切换,以及stack用来保存运行时栈。
协程状态
协程有4个状态,分别是READY、RUNNING、SUSPEND、DEAD这四个状态。状态转换如图所示:

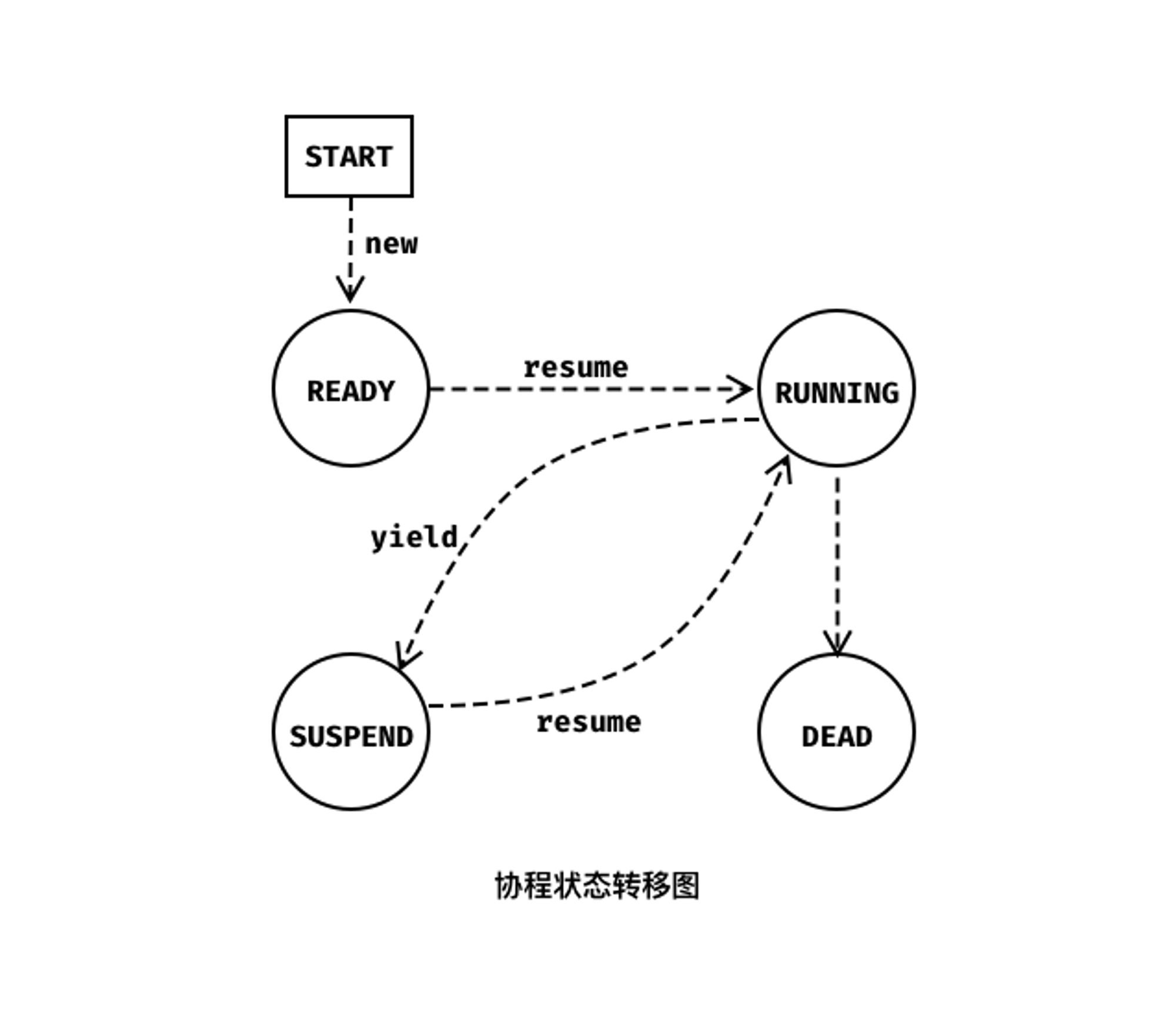
coroutine_new函数用来创建一个协程,协程进行状态转移的核心实现位于coroutine_resume函数和coroutine_yield函数中。
READY -> RUNNING
我们现看一下从READY状态转移到RUNNING状态进行的操作,和我们上面讲ucontext举的例子一样。首先,我们初始化协程的上下文,将协程的栈空间指向调度器中的共享栈,uc_link参数设定为S->main,当执行完makecontext指定的函数之后就会返回到调用coroutine_resume函数的地方。
// coroutine_resume switch(status) { case COROUTINE_READY: //初始化ucontext_t结构体,将当前的上下文放到C->ctx里面 getcontext(&C->ctx); // 将当前协程的运行时栈的栈顶设置为S->stack,每个协程都这么设置,这就是所谓的共享栈。(注意,这里是栈顶) C->ctx.uc_stack.ss_sp = S->stack; C->ctx.uc_stack.ss_size = STACK_SIZE; C->ctx.uc_link = &S->main; // 如果协程执行完,将切换到主协程中执行 S->running = id; C->status = COROUTINE_RUNNING; // 设置执行C->ctx函数, 并将S作为参数传进去 uintptr_t ptr = (uintptr_t)S; makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32)); // 将当前的上下文放入S->main中,并将C->ctx的上下文替换到当前上下文 swapcontext(&S->main, &C->ctx); break; }
RUNNING -> SUSPEND
当执行coroutine_yield函数之后,我们看到程序会首先保存当前协程的运行时栈,然后把协程的状态修改为挂起状态,并切换到主协程中。
void coroutine_yield(struct schedule * S) { // 取出当前正在运行的协程 int id = S->running; assert(id >= 0); struct coroutine * C = S->co[id]; assert((char *)&C > S->stack); // 将当前运行的协程的栈内容保存起来 _save_stack(C,S->stack + STACK_SIZE); // 将当前栈的状态改为 挂起 C->status = COROUTINE_SUSPEND; S->running = -1; // 所以这里可以看到,只能从协程切换到主协程中 swapcontext(&C->ctx , &S->main); }
SUSPEND -> RUNNING
当从挂起状态恢复为执行状态时,会将协程的运行时栈拷贝到共享栈,并再次切换上下文回到调用coroutine_yield函数的地方。
case COROUTINE_SUSPEND: // 将协程所保存的栈的内容,拷贝到当前运行时栈中 // 其中C->size在yield时有保存 memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size); S->running = id; C->status = COROUTINE_RUNNING; swapcontext(&S->main, &C->ctx); break;
运行栈保存
当执行coroutine_yield函数的时候,会发现该函数会调用_save_stack将当前协程的栈保存起来,因为coroutine是基于共享栈的,所以协程的栈内容需要单独保存起来。这里有一个很trick的点,那就是当前协程的运行栈怎么保存起来,也就是如何获取协程的栈空间。
一开始我们会在初始化调度器的时候设置共享栈的大小,stack指向栈顶,为了降低内存的占用,我们保存协程栈的时候不会直接保存一份和共享栈一样大小的栈空间,这时候我们需要找到该协程的栈顶位置。
下面代码的实现非常巧妙,他声明了一个局部变量dummy,而dummy的地址就是栈顶位置,大家可以参考上面讲的foo函数栈增长部分,相信你一定也能想到。
static void _save_stack(struct coroutine *C, char *top) { // 这个dummy很关键,是求取整个栈的关键 // 这个非常经典,涉及到linux的内存分布,栈是从高地址向低地址扩展,因此 // S->stack + STACK_SIZE就是运行时栈的栈底 // dummy,此时在栈中,肯定是位于最底的位置的,即栈顶 // top - &dummy 即整个栈的容量 char dummy = 0; assert(top - &dummy <= STACK_SIZE); if (C->cap < top - &dummy) { free(C->stack); C->cap = top-&dummy; C->stack = malloc(C->cap); } C->size = top - &dummy; memcpy(C->stack, &dummy, C->size); }
goroutine实现
golang语言中的goroutine也是一个有栈协程,但是和本文讲到的coroutine还是有很大不同,首先golang有自己的协程调度器,而且golang的协程是抢占式执行的,关于golang的协程要写的东西还是太多了,得再开一篇文章讨论,大家可以阅读下面的文章有个深入的了解。
Loading Comments...